 測試從圖片中辨識
```
from PIL import Image
import tesserocr
image = Image.open("00000.png")
with tesserocr.PyTessBaseAPI() as api:
api.SetVariable("tessedit_char_whitelist", "0123456789")
ans = tesserocr.image_to_text(image)
print(ans)
```
測試從圖片中辨識
```
from PIL import Image
import tesserocr
image = Image.open("00000.png")
with tesserocr.PyTessBaseAPI() as api:
api.SetVariable("tessedit_char_whitelist", "0123456789")
ans = tesserocr.image_to_text(image)
print(ans)
```
2019-02-25
Python 使用 Tesseract-OCR 做 Captcha 文字識別
markdown
使用 python 語言的 tesserocr 套件做 captcha 的文字驗證測試,此篇只簡要說明套件的安裝和使用。
# 簡介
在網站的登入或註冊過程,會在不同的網站遇到需要輸入驗證碼的場景,在自動化操作的過程可以透過光學文字識別(Optical Character Recognition,OCR)來將影像中的文字分析後輸出成文字。
Tesseract 是一款開源的 OCR 套件,在 python 中要使用 Tesseract-OCR 使用到 tesserocr。
## 安裝 Tesseract-OCR
首先在系統中安裝 Tesseract-OCR:
* 到 [Tesseract Wiki](https://github.com/tesseract-ocr/tesseract/wiki) 依自己使用的作業系統安裝
* Windows 安裝後要將 Tesseract-OCR 的路徑加到環境變數的 PATH 中。
將 `C:\Program Files (x86)\Tesseract-OCR` 加到 PATH 中
## 安裝 tesserocr
* Windows 系統必須下載 whl 檔安裝
step 1. 到[simonflueckiger/tesserocr-windows_build, github](https://github.com/simonflueckiger/tesserocr-windows_build/releases),下載 `tesserocr-2.4.0-cp37-cp37m-win_amd64.whl`。
step 2. 安裝 tesserocr
```
python -m pip install tesserocr-2.4.0-cp37-cp37m-win_amd64.whl
```
step 3. 設定環境設數
安裝完成要在環境變數指定 tessdata 路徑 `TESSDATA_PREFIX=C:\Program Files (x86)\Tesseract-OCR\tessdata`
如果沒有`TESSDATA_PREFIX`的路徑設定,執行時會出現找不到 tessdata path
```
RuntimeError: Failed to init API, possibly an invalid tessdata path?
```
解法一:將 `C:\Program Files (x86)\Tesseract-OCR\tessdata` 資料夾複製到 `C:\C:\Program Files\Python37\tessdata` 的資料夾
解法二:設定環境變數 `TESSDATA_PREFIX` 並指定正確的 tessdata 的路徑,設定好環境變數(可能需要重啟使用的編輯器 cmd 或 vs 才能正常取用新增的環境變數)
## 測試辨識
測試圖片 `000000.png`
測試從圖片中辨識
```
from PIL import Image
import tesserocr
image = Image.open("00000.png")
with tesserocr.PyTessBaseAPI() as api:
api.SetVariable("tessedit_char_whitelist", "0123456789")
ans = tesserocr.image_to_text(image)
print(ans)
```
測試從圖片中辨識
```
from PIL import Image
import tesserocr
image = Image.open("00000.png")
with tesserocr.PyTessBaseAPI() as api:
api.SetVariable("tessedit_char_whitelist", "0123456789")
ans = tesserocr.image_to_text(image)
print(ans)
```
Python 將 Base64 字串還原為圖片
markdown
## 取得 Base64 格式
從網站取得
```
import base64
img_data_base64 = request.POST.get("img_data")
img_b64decode = base64.b64decode(img_data_base64)
```
從檔案取得 Base64 然後將 base64 再解碼
```
import base64
img_file = open(r'image.jpg','rb')
img_b64encode = base64.b64encode(img_file.read())
img_file.close()
img_b64decode = base64.b64decode(img_b64encode)
```
# Python 圖片 Base64 解碼還原 PIL.Image 或 Opencv
Base64 解碼為 OpenCV 圖片:
```
import base64
import numpy as np
img_data_base64= request.POST.get("img_data")
img_data=base64.b64decode(img_data_base64)
img_array = np.fromstring(img_data,np.uint8)
img=cv2.imdecode(img_array,cv2.COLOR_BGR2RGB)
cv2.imshow("img",img)
cv2.waitKey()
```
Base64 解碼為 PIL.Image 圖片:
```
from io import BytesIO
from PIL import Image #pillow
img_data_base64= request.POST.get("img_data")
img_data=base64.b64decode(img_data_base64)
image = BytesIO(img_data)
img = Image.open(image)
```
OpenCV 轉換成 PIL.Image 格式:
```
import cv2
from PIL import Image
import numpy as np
img = cv2.imread("image.jpg")
cv2.imshow("OpenCV",img)
image = Image.fromarray(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
image.show()
cv2.waitKey()
```
PIL.Image 轉換成 OpenCV 格式:
```
import cv2
from PIL import Image
import numpy as np
image = Image.open("image.jpg")
image.show()
img = cv2.cvtColor(np.asarray(image),cv2.COLOR_RGB2BGR)
cv2.imshow("OpenCV",img)
cv2.waitKey()
```
參考資料來源:
https://blog.csdn.net/dcrmg/article/details/80542665
https://blog.csdn.net/qq_19707521/article/details/78403904
https://blog.csdn.net/qq_19707521/article/details/78367617
2019-02-18
Burp Suite 抓取 https 資料
markdown
因為 https 需要替換憑證才能取得資料,所以需要將 Burp Suite 的憑證安裝到瀏覽器中,這篇文章就按步驟在 firefox 中安裝 burp suite 產生的憑證,它可以抓取到 https 中的請求資料。
## 啟動Burp,確認代理已啟動 Proxy
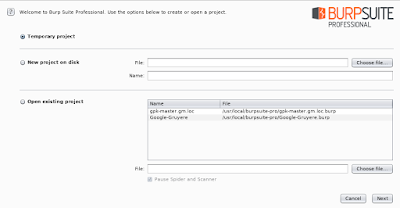
Step 1. 開一個暫時專案,下一步(Next)
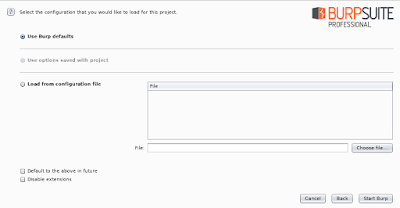
 Step 2. 使用預設設定,開啟(Start Burp)
Step 2. 使用預設設定,開啟(Start Burp)
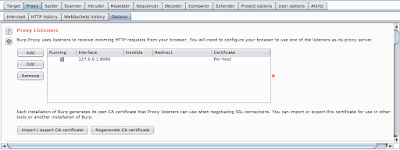
 Step 3. 檢查代理監聽(Proxy Listeners)是啟動狀態
Step 3. 檢查代理監聽(Proxy Listeners)是啟動狀態
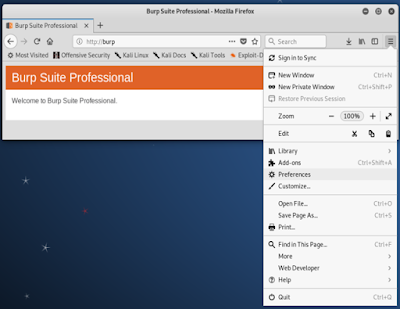
 Step 4. 開啟瀏覽器的設定(Preferences)
Step 4. 開啟瀏覽器的設定(Preferences)
 Step 5. 開啟 一般(General)/網路代理(Network Proxy) 的設定(Settings)
Step 5. 開啟 一般(General)/網路代理(Network Proxy) 的設定(Settings)
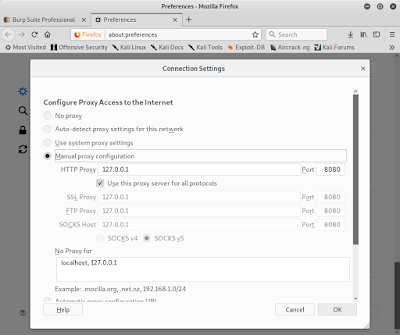
 Step 6. 填入手動設定代理。 host: 127.0.0.1, port: 8080,勾選「全部通訊協定使用這個代理(Use this proxy server for all protocols)」,按確定(OK)
Step 6. 填入手動設定代理。 host: 127.0.0.1, port: 8080,勾選「全部通訊協定使用這個代理(Use this proxy server for all protocols)」,按確定(OK)
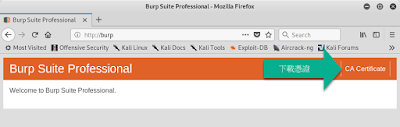
 ## 下載憑證並安裝到瀏覽器
Step 1. 瀏覽器開啟 http://burp
Step 2. 下載憑證
## 下載憑證並安裝到瀏覽器
Step 1. 瀏覽器開啟 http://burp
Step 2. 下載憑證
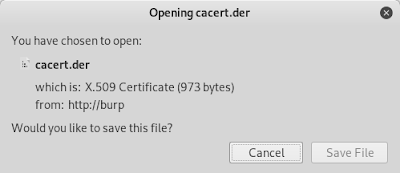
 Step 3. 將 cacert.der 儲存到 `~/download/cacert.der` 資料夾
Step 3. 將 cacert.der 儲存到 `~/download/cacert.der` 資料夾
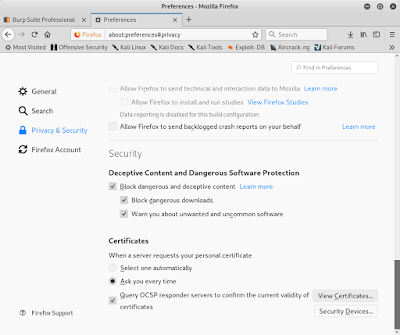
 Step 4. 開啟瀏覽器的設定(Preferences)
Step 5. 開啟「隱私和安全(Privacy & Secruity)」,找到憑證(Certificates)區段,開啟「檢視憑證(View Certificates...)」
Step 4. 開啟瀏覽器的設定(Preferences)
Step 5. 開啟「隱私和安全(Privacy & Secruity)」,找到憑證(Certificates)區段,開啟「檢視憑證(View Certificates...)」
 Step 6. 選擇 Authorities 頁籤
Step 6. 選擇 Authorities 頁籤
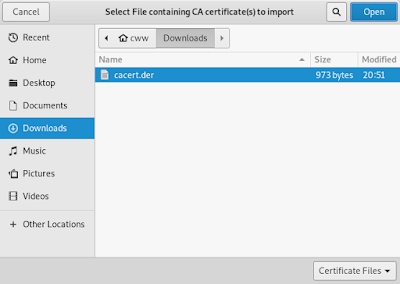
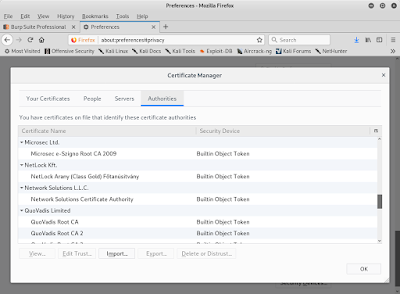 Step 7. 匯入(Import) 步驟2下載的憑證
Step 7. 匯入(Import) 步驟2下載的憑證
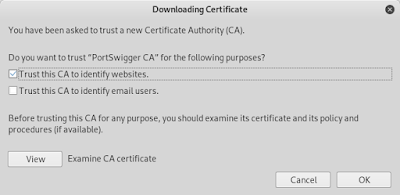
 Step 8. 勾選「信任這個網站(Trust this CA to identity websites)」,按確定(OK)
Step 8. 勾選「信任這個網站(Trust this CA to identity websites)」,按確定(OK)
 Step 9. 能在列表中看到剛才匯入的憑證「PortSwigger CA」
Step 9. 能在列表中看到剛才匯入的憑證「PortSwigger CA」
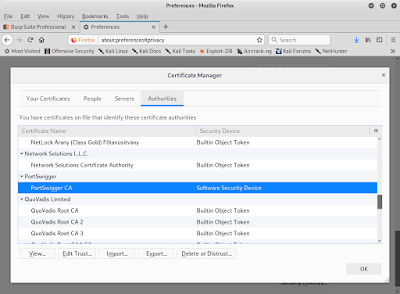 Step 10. 瀏覽器開啟 `https://www.google.com`,在網址列的驚嘆號圖型能看到網站使用的憑證被 Brup 換成 PortSwigger CA 了
Step 10. 瀏覽器開啟 `https://www.google.com`,在網址列的驚嘆號圖型能看到網站使用的憑證被 Brup 換成 PortSwigger CA 了
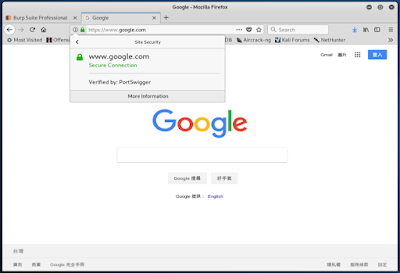 Step 11. 至此在使用 Burp 時就能攔到 https 的包嘍。
Step 11. 至此在使用 Burp 時就能攔到 https 的包嘍。

 Step 2. 使用預設設定,開啟(Start Burp)
Step 2. 使用預設設定,開啟(Start Burp)
 Step 3. 檢查代理監聽(Proxy Listeners)是啟動狀態
Step 3. 檢查代理監聽(Proxy Listeners)是啟動狀態
 Step 4. 開啟瀏覽器的設定(Preferences)
Step 4. 開啟瀏覽器的設定(Preferences)
 Step 5. 開啟 一般(General)/網路代理(Network Proxy) 的設定(Settings)
Step 5. 開啟 一般(General)/網路代理(Network Proxy) 的設定(Settings)
 Step 6. 填入手動設定代理。 host: 127.0.0.1, port: 8080,勾選「全部通訊協定使用這個代理(Use this proxy server for all protocols)」,按確定(OK)
Step 6. 填入手動設定代理。 host: 127.0.0.1, port: 8080,勾選「全部通訊協定使用這個代理(Use this proxy server for all protocols)」,按確定(OK)
 ## 下載憑證並安裝到瀏覽器
Step 1. 瀏覽器開啟 http://burp
Step 2. 下載憑證
## 下載憑證並安裝到瀏覽器
Step 1. 瀏覽器開啟 http://burp
Step 2. 下載憑證
 Step 3. 將 cacert.der 儲存到 `~/download/cacert.der` 資料夾
Step 3. 將 cacert.der 儲存到 `~/download/cacert.der` 資料夾
 Step 4. 開啟瀏覽器的設定(Preferences)
Step 5. 開啟「隱私和安全(Privacy & Secruity)」,找到憑證(Certificates)區段,開啟「檢視憑證(View Certificates...)」
Step 4. 開啟瀏覽器的設定(Preferences)
Step 5. 開啟「隱私和安全(Privacy & Secruity)」,找到憑證(Certificates)區段,開啟「檢視憑證(View Certificates...)」
 Step 6. 選擇 Authorities 頁籤
Step 6. 選擇 Authorities 頁籤
 Step 7. 匯入(Import) 步驟2下載的憑證
Step 7. 匯入(Import) 步驟2下載的憑證
 Step 8. 勾選「信任這個網站(Trust this CA to identity websites)」,按確定(OK)
Step 8. 勾選「信任這個網站(Trust this CA to identity websites)」,按確定(OK)
 Step 9. 能在列表中看到剛才匯入的憑證「PortSwigger CA」
Step 9. 能在列表中看到剛才匯入的憑證「PortSwigger CA」
 Step 10. 瀏覽器開啟 `https://www.google.com`,在網址列的驚嘆號圖型能看到網站使用的憑證被 Brup 換成 PortSwigger CA 了
Step 10. 瀏覽器開啟 `https://www.google.com`,在網址列的驚嘆號圖型能看到網站使用的憑證被 Brup 換成 PortSwigger CA 了
 Step 11. 至此在使用 Burp 時就能攔到 https 的包嘍。
Step 11. 至此在使用 Burp 時就能攔到 https 的包嘍。

訂閱:
意見 (Atom)